LeetCode 第 139 题:“单词拆分”题解
题解地址:动态规划(Python 代码、Java 代码)。
说明:文本首发在力扣的题解版块,更新也会在第 1 时间在上面的网站中更新,这篇文章只是上面的文章的一个快照,您可以点击上面的链接看到其他网友对本文的评论。
传送门:139. 单词拆分。
给定一个非空字符串 s 和一个包含非空单词列表的字典 wordDict,判定 s 是否可以被空格拆分为一个或多个在字典中出现的单词。
说明:
拆分时可以重复使用字典中的单词。 你可以假设字典中没有重复的单词。 示例 1:
输入: s = "leetcode", wordDict = ["leet", "code"] 输出: true 解释: 返回 true 因为 "leetcode" 可以被拆分成 "leet code"。 示例 2:
输入: s = "applepenapple", wordDict = ["apple", "pen"] 输出: true 解释: 返回 true 因为 "applepenapple" 可以被拆分成 "apple pen apple"。 注意你可以重复使用字典中的单词。 示例 3:
输入: s = "catsandog", wordDict = ["cats", "dog", "sand", "and", "cat"] 输出: false
动态规划(Python 代码、Java 代码)
方法:动态规划
这是一个可以使用动态规划解决的问题。
 ,
, ,
, ,
, ,
, ,
, ,
,
参考代码 1:状态的定义为:以 s[i] 结尾的子字符串是否可以被空格拆分为一个或多个在字典中出现的单词。
from typing import List
class Solution:
def wordBreak(self, s: str, wordDict: List[str]) -> bool:
size = len(s)
# 题目中说非空字符串,以下 assert 一定通过
assert size > 0
# 预处理,把 wordDict 放进一个哈希表中
word_set = {word for word in wordDict}
# print(word_set)
# 这种状态定义很常见
dp = [False for _ in range(size)]
dp[0] = s[0] in word_set
# 使用 r 表示右边界,可以取到
# 使用 l 表示左边界,也可以取到
for r in range(1, size):
# Python 的语法,在切片的时候不包括右边界
# 如果整个单词就直接在 word_set 中,直接返回就好了
# 否则把单词做分割,挨个去判断
if s[:r + 1] in word_set:
dp[r] = True
continue
for l in range(r):
# dp[l] 写在前面会更快一点,否则还要去切片,然后再放入 hash 表判重
if dp[l] and s[l + 1: r + 1] in word_set:
dp[r] = True
# 这个 break 很重要,一旦得到 dp[r] = True ,循环不必再继续
break
return dp[-1]
if __name__ == '__main__':
s = "leetcode"
wordDict = ["leet", "code"]
solution = Solution()
res = solution.wordBreak(s, wordDict)
print(res)
Java 代码:
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
public class Solution {
public boolean wordBreak(String s, List<String> wordDict) {
int len = s.length();
// 状态定义:以 s[i] 结尾的子字符串是否符合题意
boolean[] dp = new boolean[len];
// 预处理
Set<String> wordSet = new HashSet<>();
for (String word : wordDict) {
wordSet.add(word);
}
// 动态规划问题一般都有起点,起点也相对好判断一些
// dp[0] = wordSet.contains(s.charAt(0));
for (int r = 0; r < len; r++) {
if (wordSet.contains(s.substring(0, r + 1))) {
dp[r] = true;
continue;
}
for (int l = 0; l < r; l++) {
// dp[l] 写在前面会更快一点,否则还要去切片,然后再放入 hash 表判重
if (dp[l] && wordSet.contains(s.substring(l + 1, r + 1))) {
dp[r] = true;
// 这个 break 很重要,一旦得到 dp[r] = True ,循环不必再继续
break;
}
}
}
return dp[len - 1];
}
public static void main(String[] args) {
String s = "leetcode";
List<String> wordDict = new ArrayList<>();
wordDict.add("leet");
wordDict.add("code");
Solution solution = new Solution();
boolean res = solution.wordBreak(s, wordDict);
System.out.println(res);
}
}
参考代码 2:状态:dp[i] 表示子串 s[0:i] (即长度为 i 的子串,其实就是前缀)可以被空格拆分,并且拆分以后的单词是否落在 wordDict 中。这里 wordDict 要把它放入哈希表中,以快速判断一个单词是否在这个哈希表里。
如图所示。
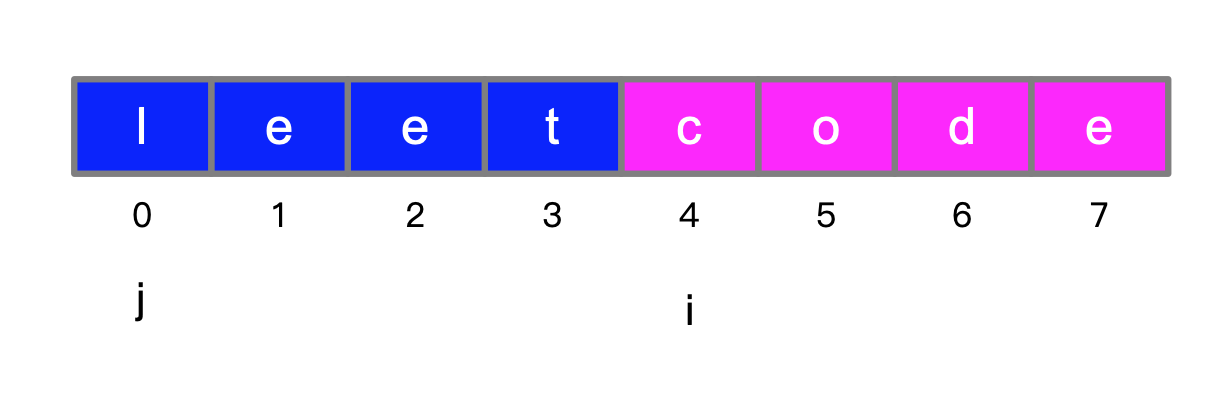
如果以 j 作为边界,后面的部分在 wordDict 中,前面的部分又满足题意,那么长度为 i 的 s 的前缀子串就满足题意。我们可以将 i 从 开始填写,直到 len(s) 为止。
状态转移方程:dp[i] = s[j:i] in wordDict and dp[j]。
注意 1:需要长度为 的状态,且定义为 True,因为如果字符串本身就在 wordDict 中,就不必看 dp 了,可以直接判断为 True,因此 dp[0] = True;
注意 2:注意边界条件:后数组的起始索引,表示了前数组的长度;
注意 3:一旦得到 dp[i] = True 就可以退出循环了,j 就无须遍历下去。
from typing import List
class Solution:
def wordBreak(self, s: str, wordDict: List[str]) -> bool:
size = len(s)
# 题目中说非空字符串,以下 assert 一定通过
assert size > 0
# 预处理,把 wordDict 放进一个哈希表中
word_set = {word for word in wordDict}
# 状态定义:长度为 i 的子串可以被空格拆分为一个或多个在字典中出现的单词
dp = [False for _ in range(size + 1)]
dp[0] = True
# 使用 r 表示右边界,可以取到
# 使用 l 表示左边界,也可以取到
for r in range(1, size + 1):
for l in range(r):
# dp[l] 写在前面会更快一点,否则还要去切片,然后再放入 hash 表判重
if dp[l] and s[l: r] in word_set:
dp[r] = True
# 这个 break 很重要,一旦得到 dp[r] = True ,循环不必再继续
break
return dp[-1]
Java 代码:
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
public class Solution2 {
public boolean wordBreak(String s, List<String> wordDict) {
int len = s.length();
// 状态定义:长度为 i 的子字符串是否符合题意
boolean[] dp = new boolean[len + 1];
// 预处理
Set<String> wordSet = new HashSet<>();
for (String word : wordDict) {
wordSet.add(word);
}
// 这个状态的设置非常关键,说明前部分的字符串已经在 wordSet 中
dp[0] = true;
for (int r = 1; r < len + 1; r++) {
for (int l = 0; l < r; l++) {
// dp[l] 写在前面会更快一点,否则还要去切片,然后再放入 hash 表判重
if (dp[l] && wordSet.contains(s.substring(l, r))) {
dp[r] = true;
// 这个 break 很重要,一旦得到 dp[r] = True ,循环不必再继续
break;
}
}
}
return dp[len];
}
public static void main(String[] args) {
String s = "leetcode";
List<String> wordDict = new ArrayList<>();
wordDict.add("leet");
wordDict.add("code");
Solution2 solution2 = new Solution2();
boolean res = solution2.wordBreak(s, wordDict);
System.out.println(res);
}
}